Frequently Asked Questions
How much does Databrary cost?
For the time being, there is no cost to use Databrary.
However, consistent with the practices of peer data repositories and data services (ICSPR, Data Dryad, FigShare) we are developing a fee-for-service and subscription model that we will implement in late 2025. We encourage researchers with large datasets who are writing funding proposals to contact us in advance so that suitable data curation and storage fees can be included in the grant budget.
How is Databrary funded?
Databrary is supported through grants from federal agencies, and private foundations.
Where is Databrary located?
Databrary is located at New York University (NYU). All data is stored on servers that are maintained by NYU IT staff.
Does Databrary offer “blind review”?
Databrary is a restricted access data repository that promotes the storage and sharing of identifiable and sensitive data. As such, Databrary has unique policies to protect the privacy of research participants. These policies govern who can access identifiable data and under what circumstances. The policies are codified in a formal access agreement that binds NYU, Databrary’s parent institution, and similar institutions where Databrary’s users conduct research. For the forseeable future, these policies make it impossible to support full double-blinded anonymous review of data and materials.
While some data and materials are shared with the public, Databrary restricts access to sensitive and identifiable information to people who have received authorization from an institution or to those whose access is supervised by an authorized investigator. Only authorized investigators can create and share datasets. Dataset creators, not Databrary, determine what level of sharing is appropriate for individual data files and for datasets as a whole.
So, the level of access a reviewer can have to a dataset depends on two things: Has the dataset been shared with the Databrary community? Does the reviewer have authorization from an institution to view restricted data or materials?
If both answers are yes, the reviewer may fully vet a shared dataset. Databrary does not report on access to specific datasets, so the reviewer can remain anonymous. Databrary does not mask the identities of dataset owners, so the blinding is only one-way.
If the dataset is shared, but the reviewer does not have authorization from an institution, the reviewer can confirm that a shared dataset exists, that the dataset has a persistent identifier, and that the dataset has a specific number of shared restricted access files. The reviewer may also examine any items that are shared with the public, stimuli, protocol, aggregated and de-identified datasets, etc.
How do I fix an audio file that is not playing in Databrary?
- Download original session from Databrary and unzip the file
- Open the free audio editing program Audacity
- Open the file.
- Select the downloaded file from the appropriate folder, usually the ownloads folder
- Go to File > export > export as MP3
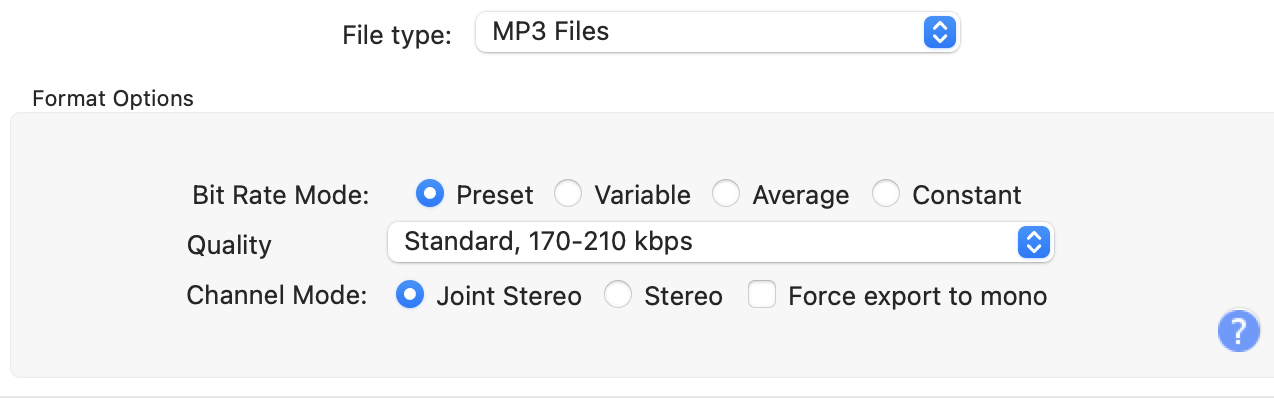
- Use the following default parameters
- If your file is named incorrectly (e.g. spaces/brackets/filename truncated) please edit the filename here.
A window pops up called ‘edit metadata tags’. just select OK
This new file needs to be replaced in the Databrary session folder.
How do I fix a video file that is not streaming in the Databrary application?
If you ever find that there are videos that don’t play in Databrary, the following instructions may be helpful to you.
- use Handbrake (https://handbrake.fr/) to convert/transcode these files to .mp4 (this will change and fix the file if there is any corrupted block)
- Go back to the session
- highlight the video
- click on the pencil in the upper left corner to edit
- click on ‘replace’ in the upper right corner
The recommended settings in Handbrake that duplicate the .mp4 codec that Databrary uses during the transcoding process after a video file is uploaded are below. These settings may also be downloaded as a .json file and imported into Handbrake
| Summary | Dimensions | Filters | Video | Audio |
|---|---|---|---|---|
| Format = MP4 | Cropping = None | Deinterlace = Decomb | Video Encoder = H.264 (x264) | Codec = AAC (CoreAudio) |
| Select “passthru” metadata | Resolution Limit = 1080p HD | Framerate (FPS) = Same as source | Mixdown = 2ch Stereo audio (force to 2ch mixdown) | |
| Align A/V Start | Anamorphic = Automatic | Variable Framerate | ||
| H.264 (x264) VFR video | Select ‘Optimal Size’ | Quality = Constant Quality |
Oops, I uploaded the wrong file in my session. Can I replace it?
Yes! Please follow these instructions:
- Login to Databrary
- Click on ‘Your Profile’ in the center of the screen
- Navigate to the appropriate volume
- Then the appropriate session
- Single Click on the file that needs to be replaced.
- Click on the Edit Button (the small pencil)
- Ensure the appropriate file is highlighted in gray.
- Click ‘Replace File’ at the top right of the screen
- Navigate in the files pane to the correct file then select Open
I just uploaded a video file onto Databrary and it says my uploading is complete. Why can’t I see it on or download it from Databrary right away?
When you upload a video or audio file, Databrary converts it (transcodes it) into a common format that should be accessible well into the future. The original file format is stored in parallel. Transcoding videos takes time. Databrary will not show a thumbnail of your file until the transcoding finishes. If your file is especially large, then the wait time could be several hours.
If your file takes longer than that, contact Databrary support. Sometimes, transcoding jobs fail, and we can fix the problem at our end.
I downloaded files from Databrary, but the filenames are truncated.
When you download files from the Databrary application, the system appends information about the volume and session the files came from. This is to help you understand what you’ve downloaded. However, when Databrary downloads files there is a 32 character limit to the file name. So, if your file on Databrary has a long name, some of that name may be truncated in the downloaded file. Or, if the file name is too long (the first 32 characters of the filename are exactly the same as another file), it is impossible to distinguish between these files when they download and only one file will be downloaded.
There are two solutions:
- Try not to create excessively long file names for files stored on Databrary.
- Alternatively, you may want to download and use the databraryr R package. The package includes commands to download files from Databrary with the original (full length) Databrary file names intact. See this section of the databraryr guide for more information.
I have a multi-site study. Is there a recommendation on volume/file naming schemes?
Try naming the each Volume: ProjectName_SITEID
The Short Name is INTERNAL only to volume Investigators and Collaborators
Where each SITEID has a unique id to each site, typically with the same number of characters.
Each file uploaded can have a standard naming scheme which includes the SITEID.
In the Volume Description, list the name of the university/institution in full. This allows for use of an API pull to ingest data when necessary.
After all data are collected, a new volume with ALL of the final data, including which data are from which site, can be created.
Is there a storage capacity limit for each project?
At the moment, no.
When we implement our fee-for-service/subscription model later in 2024, we will likely impose project-, researcher-, and institution- level limits for new projects that do not pay or subscribe.
Is there a maximum file size? We have some multigig videos and want to check ahead of time if there is a limit
At the moment, no.
However, we do not guarantee that large videos will transcode or stream well.
If you need to download videos en masse or large videos, please consider using the databraryr package. It can be much faster than the web application.
We are still drafting responses to the following questions: