Planning
About
This page provides information about project meetings and project planning.
Sprint planning 2025-05-09
Resources
- Document describing one possible spreadsheet data model.
Kick-off 2025-03-10
Attendees
- Databrary: Rick Gilmore, Karen Adolph, Kasey Soska, Andrea Seisler
- NYU IT: Ken Yelton, Julian Quintero
- Montrose Software: Olha Hnatiuk, Miroslaw Syzdek
Agenda
Overview
- What and why
Aims/Projects
- Aim 1: Accelerate data reuse through enhanced data discovery
- Project 1.1: Update Databrary’s search engine and user interfaces
- Project 1.2: Update Databrary’s backend to support storage of multiple annotation layers and develop interfaces to depict multiple annotation layers
- Aim 2: Ease data reuse with custom collections that automatically track provenance across sources
- Project 2.1: Create new custom collections of shared videos for reanalysis
- Aim 3: Expand data sharing via workspaces that support active curation, thereby reducing the lag between data analysis and open sharing
- Project 3.1: Implement “workspaces” for in-progress research projects
- Project 3.2: Update Databrary’s UI to permit flexible views of datasets
- Aim 4: Promote research transparency and reproducibility by expanding scriptable access to Databrary functions
- Project 4.1: Polish, document, and promote Databrary’s API
- Project 4.2: Update databraryr and develop and release a Python package, databrarypy, for accessing Databrary
- Project 4.3: Create and publish sample scripts and introduce the new automation tools to the research community
- Aim 5: Enhance the value of existing data stored on Databrary by adding searchable metadata and sharing unshared data
- Project 5.1: Make existing shared datasets more readily findable
- Project 5.2: Curate unshared datasets and release them for wider use
Governance
- Staffing/roles
- Advisory board
- Communications
Timeline
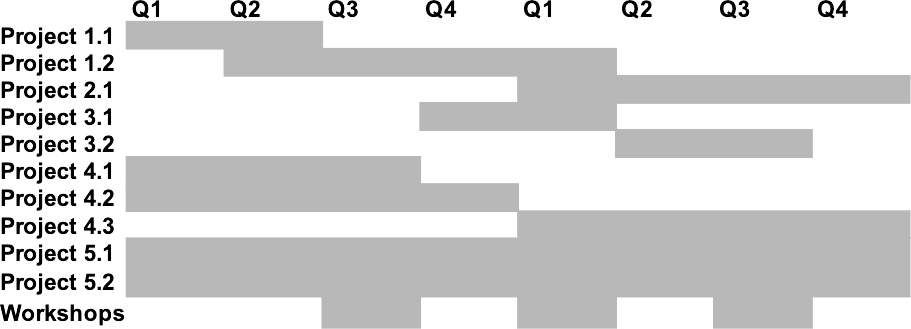
Follow-up
- Return to two-week sprints, starting 2025-03-11
- Plan to focus on DB2.0 deliverables first
- Begin planning Custom Collections (Aim 2)
Custom Collections
- See Aim 2/Project 2.1
Use cases
- Select files, sessions, volumes shared by others and clone them to my own volume
- Add select box to UI?
- Bookmark/shopping cart metaphor for UI
- Volume owner notification
- Notify that files were cloned, but not by whom?
- Part of volume-level analytics
- Maintain file provenance
- UI indicates cloned files
- Backend links to citation/source
- New annotation layers add link back to source volume
- How do annotation files get linked to source video/audio in backend?
- Custom collections can include cloned and new material
- Edge cases
- What happens to cloned items if original owner modifies or deletes them?
- What happens to shared volumes containing cloned material when the owner modifies or deletes them?
- Who can create custom collections?
- Must have account
- Premium feature (at member institution)?
- Have read privileges on private volume
Search
- See Aim 1/Project 1.1
Use cases/user stories
- Prioritize search based on user’s recent searches, their own volumes.
- Separate or make selectable search for volumes, institutions, users, files/videos
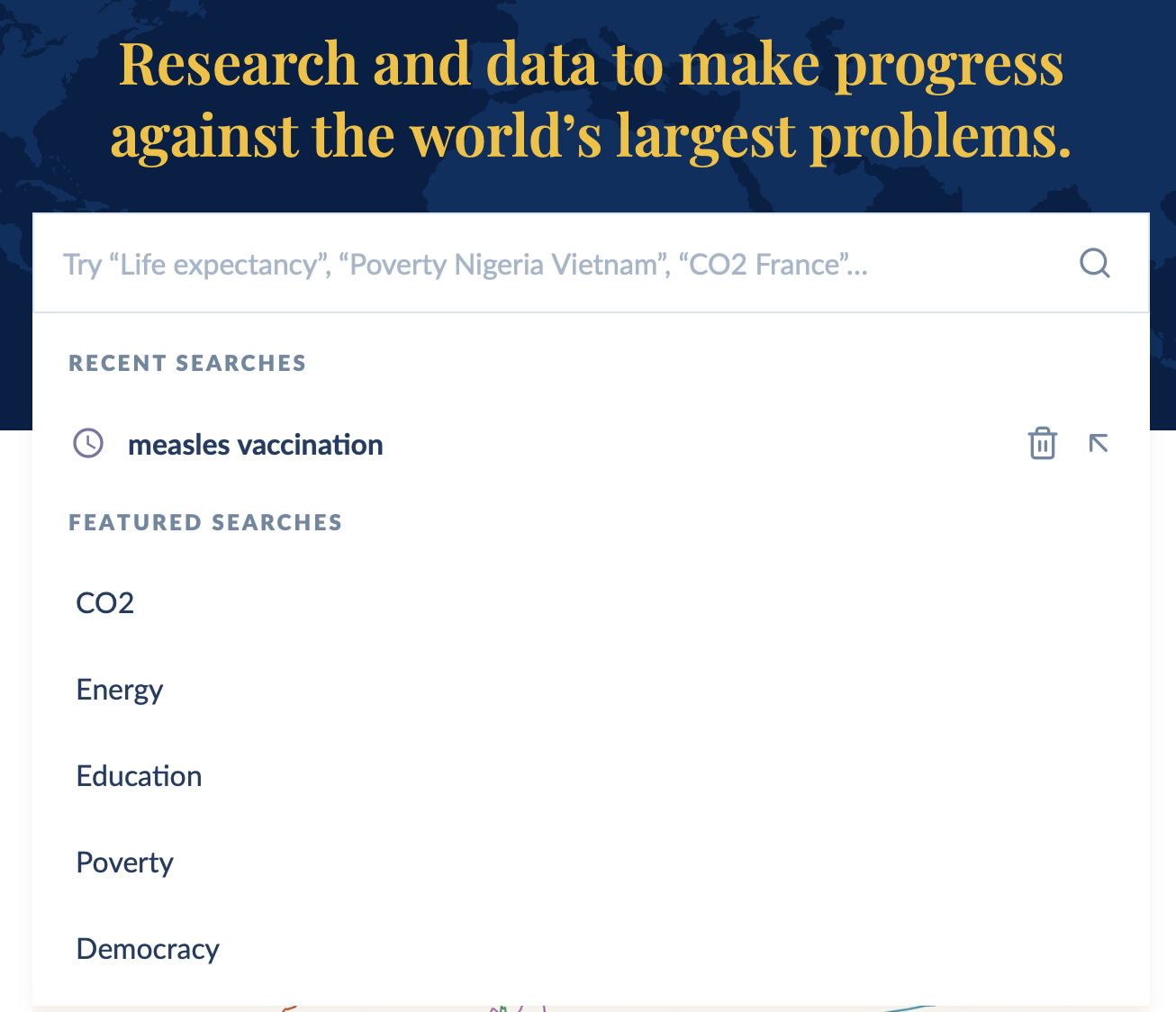
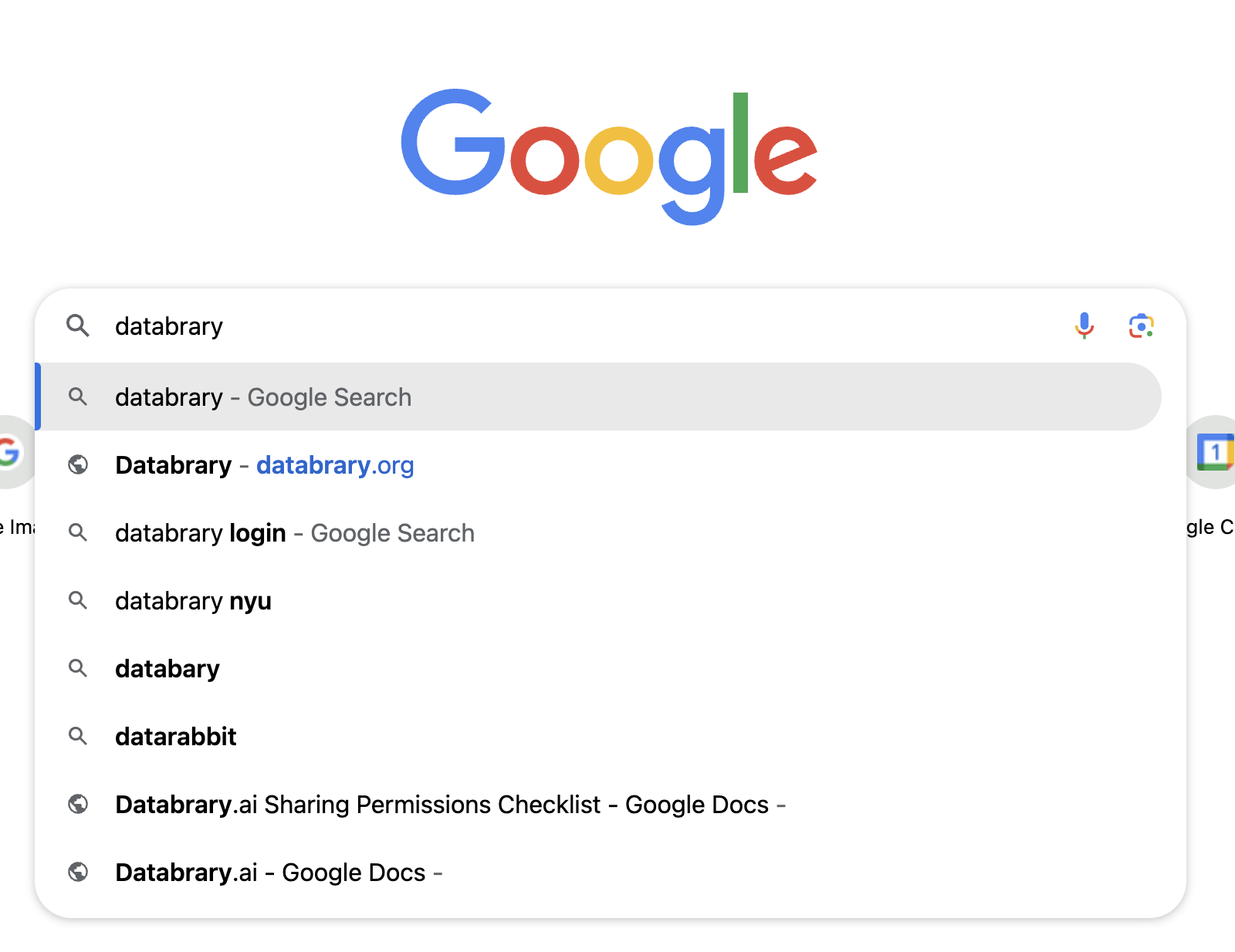
- Suggest “popular” searches, see screenshot from Our World in Data. Also Google Search screenshot.
{kind=link}
{kind=link}
Active tickets
- https://montrose.atlassian.net/browse/DAT-213?atlOrigin=eyJpIjoiNDIyZDU5MWVkZjMwNDEzYjhlOTI2Zjc0NWYyNDk1NjAiLCJwIjoiaiJ9
- https://montrose.atlassian.net/browse/DAT-302?atlOrigin=eyJpIjoiZDUwZmFlZjg4MzE2NGE4ZGI3MzU2MzJhN2YwMTVhZmIiLCJwIjoiaiJ9
- https://montrose.atlassian.net/browse/DAT-303?atlOrigin=eyJpIjoiNDg2YjVkYmZiOTk5NDQxYTgyNGQzYmMxNDdjNDc4YzUiLCJwIjoiaiJ9
- https://montrose.atlassian.net/browse/DAT-864?atlOrigin=eyJpIjoiOGExMWY3Njg2YjczNDQ5Mzk5YjRkMjQzODlmZWU4NjkiLCJwIjoiaiJ9
- Index text in papers a volume links to. https://montrose.atlassian.net/browse/DAT-862?atlOrigin=eyJpIjoiYmRhMjEzN2VhYWZiNDI0YmFlZTU3ZDc3OWFjN2JlZjQiLCJwIjoiaiJ9